
Note: This is an edited version of research we put together for CanIRank Full Service clients. This is part 1, What is a broad core algorithm update?, part 2 dives into data around What changed in in the Google Medic Update?, and part 3 (coming soon!) explains How to Recover from the Google Medic Algorithm Update.
As a team that combines marketers with data scientists and engineers, we believe a key part of an SEO consultant’s job is to help clients understand how Google’s high-level objectives like “make great content” or “become the leading authority in your field” translate into actual machine-readable signals, and how you can improve your content marketing processes to strengthen those signals while still balancing other business objectives.
This 3-part series on Google’s latest core algorithm update (“Medic Update”) is our attempt to help elevate the conversation around algorithm updates to more of an evidence-based exploration focused on specific algorithmic signals rather than intangible high-level objectives.
On August 1st, Google’s Search Liaison Danny Sullivan tweeted that the company was rolling out a “broad core algorithm update”, since branded by some the “Medic Update” due to the outsized impact it had on sites in the health niche.
This week we released a broad core algorithm update, as we do several times per year. Our guidance about such updates remains the same as in March, as we covered here: https://t.co/uPlEdSLHoX
— Google SearchLiaison (@searchliaison) August 1, 2018
Within hours, SEOs began speculating about what had changed, and the first blog posts claiming to know how to fix traffic declines were published before the update had even fully rolled out.
The most common analysis was that this update centered on “E-A-T”: Expertise, Authority, and Trust, three of the factors Google asks its Search Quality Evaluators to consider. “Fixing” your E-A-T requires steps like bolstering your About page and author profile pages to emphasize credentials and expertise, as well as building up your authority on sites like Wikipedia, LinkedIn, and other social media.
Although no data or even examples beyond a single keyword were presented to support this assertion, in the echo chamber of the SEO blogosphere it was a matter of days before this analysis became accepted as a foregone conclusion.
Those who claimed to understand what was going on before the algorithm had even rolled out were rewarded with dozens of links and hundreds of emails from potential clients desperate to reverse their rankings drops.
There’s only one problem: their advice is wrong.
It’s not bad advice per se. Bolstering your About page, contact info, or author profiles is a fine way to improve your website, but if you’re looking for a path to recovery from the Medic update, you’ll need to understand that this update was about much more than E-A-T.
Once we dive into actual data, we’ll see none of the “fixes” recommended by SEO bloggers in the E-A-T camp are strongly associated with ranking increases in the August algorithm update. Again, that doesn’t mean they won’t help or they’re not a valid improvement, but if you’re trying to diagnose why your website declined, you should know that data shows other factors played a much bigger role in declines.
A few SEO consultants took the time to do a bit of their own research, or perhaps have enough understanding of how machine learning algorithms work to question how some of the above factors would be translated into robust machine-readable signals.
I’m skeptical of this whole E-A-T business, as extrapolated from the Quality Raters guidelines. Google has always leaned into engineering solutions that scale, and I can’t to see how this one isn’t an army of potentially iffy signals for them 2/
— Matthew J. Brown (@MatthewJBrown) August 7, 2018
But so far no one has shared much in the way of hard data around which factors sites that benefitted from this update had in common, and which factors seem to have led to declines.
Given our high regard for data and not-so-high regard for SEO “gurus”, we thought it would be helpful for our CanIRank Full Service clients if we used CanIRank’s Competitive Analysis software to collect data on some gaining and losing sites so that we could make informed recommendations as to how to adjust strategies accordingly.
Although the study is still ongoing, our initial findings were so striking that we decided it was important to publicly share the results before thousands of struggling webmasters spend their last dollar trying to beef up their About page or hire an M.D. to write their blog posts.
In this post, we’ll present a case for why we think this should have been called the “Query Intent Update”, why adjustments to treatment of query intent impacted some industries more than others, and what you need to know to adapt your SEO processes to this new reality moving forward.
- What is a “Broad Core Algorithm Update”?
- What is Google Trying To Fix?
- Losers impacted
- Gainers impacted
What is a “Broad Core Algorithm Update”?
- More than one change
- Weighting of different components
- Strengthening the role of query intent
A “broad core algorithm update” suggests that changes were made across a variety of factors, and not just in a specific industry (eg, health) or query type such as YMYL (“Your Money or Your Life” = queries with potential to impact a searcher’s physical or financial well-being).
We looked at over 100 examples of medium-large sites that saw a significant shift to the positive or negative, and about 35-40% could be broadly defined as “Health, Diet, & Lifestyle” sites.
Does that mean Google was specifically targeting YMYL sites, or that the modified factors happened to be particularly present in Health?
To answer that we first need to understand query intent, Google’s estimation of what a user is trying to accomplish when they make a given query. For example, if I search “buy climbing rope” or “REI near me”, it’s pretty easy to figure out I have a shopping intent or navigational intent, respectively.
Google can weight ranking factors differently in order to serve a better result for that specific intent. So for the shopping query they may put extra emphasis on structured data for pricing, reviews, and inventory, or 3rd-party assessments of shopper satisfaction. For navigational queries Google wants to make sure they know the physical location of a business.
One interpretation of “core algorithm” is the weighting of different factors in response to query intent. Some of those queries are entire algorithms in themselves, like Panda (Website Quality) or Penguin (overdoing links or optimization).
Here’s a visualization of what that might look like, from a slide I shared at the Ungagged conference a couple years back:
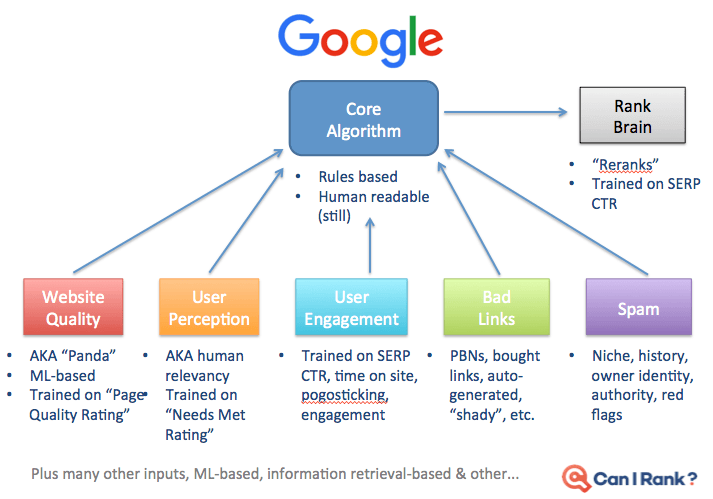
For each query intent, Google might use a different mix of signals and different weightings:
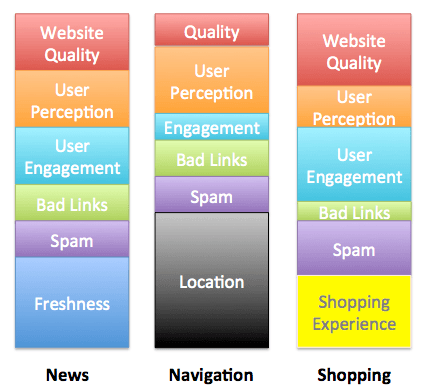
When the core algorithm changes, the impact may be more dramatic for certain query intents as new factors are introduced or weightings changed:
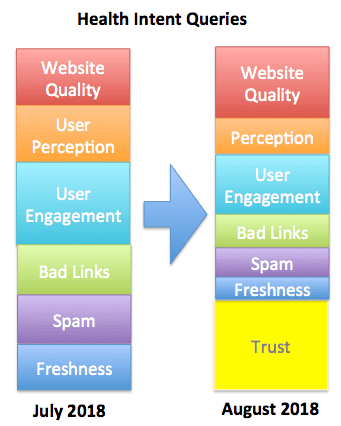
There’s no need for component weightings to be fixed or even finite in number. One of the things that Deep Learning algorithms do really well is create features from composites of lower-level inputs, so RankBrain (which has been described by Google engineers as “re-ranking” certain SERPs) could function to determine weightings for queries of mixed or unknown intent.
Regardless of whether or not you consider inputs to the “core algorithm” to be individual features or aggregate components, a “broad” change to that algorithm suggests that multiple factors were changed, so we should be looking for multiple potential causes for sites to increase or decrease their ranking. In addition, those causes should vary depending on the query intent.
And sure enough, once we dived into the data on what changed in Google’s Medic Update, that’s exactly what we found…
What is Google Trying To Fix?
- Media and public opinion no longer forgiving of FAANG missteps
- Excessive power of networks
- Relevancy doesn’t always equal satisfaction
Before we get in to analyzing the study data, it might be helpful to think a bit about what Google is trying to improve here. Although Google always claims they’re putting the interests of the user first, when you look back over the history of Google algorithm changes, you’ll see that they’re often reacting to bad press, public opinion, or other threats to their business.
Fake News, Meet Fake Medical Advice
2018 has seen an unprecedented level of press and public smackdown on Big Tech (particularly Facebook), with FAANG taking the blame for everything from Trump to inflated real estate costs to teenage depression.
I imagine Google is especially sensitive right now about anything that could lead to bad press. Observing the drubbing Facebook and others have been receiving over false or misleading political reporting, how would the public react to stories that someone died or was seriously injured because the “healing crystals” they bought online to cure their appendicitis didn’t turn out to be the miracle cure that top ranking natural treatments blogger promised?
Already, it’s no secret that Doctors aren’t always thrilled about the information their patients find online:

What is the ideal user experience for this particular query intent?
I mentioned that the August update was much bigger than just the health niche. We’ve seen sites dramatically impacted in ecommerce, auto, financial services, SaaS startups, pop culture, coupons, product reviews, and more.
Many of the impacted sites are leading authorities in their niche, with content quality and expertise that rivals any site on the internet (including the subset that saw increases). They must be extremely frustrated with all of the SEO media and experts telling them that this update targets health and only demotes sites with inadequate Expertise / Authority / Trust.
Viewed through the lens of query intent, however, we start to see how these sites may do a great job of satisfying users in general, but they have weaknesses when it comes to more specific query intents.
As a thought experiment, let’s picture a team of brilliant Google engineers gathered in a cutely-named conference room with a huge pile of free organic, gluten-free, fair-trade snacks.
“What would the ideal user experience be for someone searching a health query?” the bearded guy in a $200 pre-aged flannel asks.
“Well, he or she wants thorough, well-written information from a site they can trust with no qualms whatsoever”, the eager intern chimes in.
“And most importantly it needs to be accurate! Especially since we’ll increasingly be scraping this content for our own answer boxes, the last thing we want is another public snafu over calling Republicans Nazis or Obama the Emperor of the United States,” says the MBA in the corner, easily identifiable as the only one wearing shoes made from animal products.
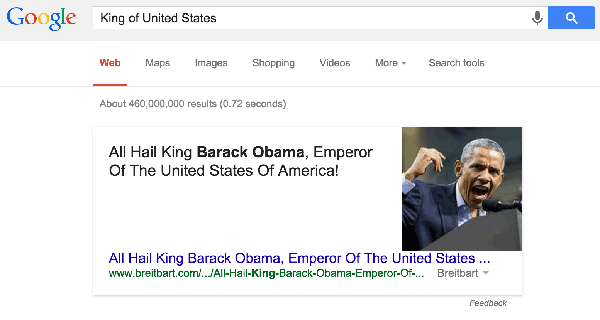
Yes, this was an actual featured snippet
Further brainstorming might reveal a list of qualities that defines an ideal search experience for other query intents:
- A shopping query should lead to trustworthy retailers in your local market where the product is in stock, priced competitively, well described, and reviewed by third parties. The retailer should have customer-friendly policies like free shipping, easy returns, and great customer service.
- An informational query should lead to pages that have high quality, objective, well-presented information that isn’t flooded with ads or trying to pass off infomercial-style content as informative. Sites hawking specific products aren’t credible sources of information.
- A financial services query should lead to pages that fairly educate consumers about all options rather than pushing one specific solution. They should disclose conflicts of interest and be on sites that users can trust.
From these brainstorming sessions our Googler heros could emerge with a long list of signals to reward or punish for any given query type. Then they can see what the results look like with different weightings of these signals, and evaluate performance by running those results by their army of Search Quality Evaluators.
But there’s a catch.
The above scenario, if it happened at all, would have happened way back in 2002, if not earlier.
In 2018, no self-respecting engineer worth her Stanford degree would endorse such a solution: it doesn’t scale well or adapt to changes, and would be a nightmare to maintain.
To understand how Google works, think like an Engineer
This is 2018. We now have much more sophisticated machine learning algorithms who can do this kind of thinking without requiring gluten-free snacks.
One area that has seen considerable development is Deep Learning. The unique aspect of Deep Learning algorithms is that they can essentially create and select their own signals.
It’s easier to see how this might be applicable looking at other areas like image recognition. Previously, most image recognition algorithms looked at pictures on a pixel-by-pixel basis: this arrangement of pixels is a cat, and that one is a stop sign.
If you think about it, looking at the whole picture is a terribly inefficient way to identify an image. My 2-year old uses a different algorithm: if she sees black-and-white stripes, she’s going to call something a zebra. A trunk means it’s probably an elephant, and a long narrow body is probably a snake. (Okapis and skinks are still a challenge.) In other words, humans don’t need to take in every pixel to identify something, because we’ve identified higher-level signals that are especially predictive.
Deep Learning works similar to 2-year olds. The middle layers of a Deep Learning neural net identify certain higher-level patterns that are especially predictive, such as stripes for a zebra, or an octagon shape for stop signs.
Sidebar for the black hats out there, this characteristic means that Deep Learning algorithms are easily fooled by abstract images that incorporate only the higher-level signals:

Using Deep Learning, we don’t need to define an ideal user experience for each query intent, we just need to define what a satisfied user looks like. So we might measure a user’s satisfaction with a specific result using:
- CTR
- Dwell time on the result page
- Interaction with the result page
- Conversion on the result page
- Clicks on other results
- Further search queries
- Etc…
With a User Satisfaction score defined, a Deep Learning algorithm could determine sets of signals with much more nuance, at least for those never-before-seen queries without clear intent (“hello Voice Search!”). An ambiguous query like “toddler room” can include a mixture of shopping, informational, and local results, and that mixture can change by location or over time in response to shifting user preferences.
“The Latest in a Series of Improvements”, All Focused on Query Intent
If you still don’t believe me that this algorithm update should have been named the “Query Intent Update” rather than the Medic Update, consider that the number of Google queries displaying “People also ask” boxes jumped 35% the week before this algorithm was introduced, and are now shown for almost half of all queries.
What is the “People also ask” box but a chance for searchers to clarify the intent of their query?
I believe the timing of this rollout was intentional and closely related: “Hey, before we push live the Query Intent Update, let’s make sure to up the number of queries displaying query refinement boxes so that people can easily clarify if we get the experience wrong.”
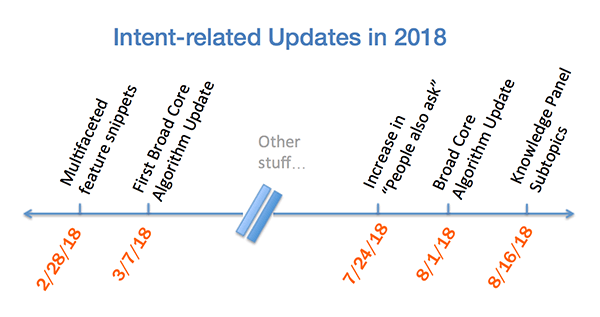
Notice any patterns?
Moreover, August 2018 is not even the first time they’ve done this. In late February / early March of this year, there was another update that Google referred to only as a “Broad, Core Algorithm Update”. The two are so closely related that Google’s Search Liaison announced the August Update by tweeting “Our guidance remains the same as in March”.
As in August, the March “Broad, Core Algorithm Update” was accompanied by other Query Intent related feature rollouts, such as multifaceted feature snippets. Batched feature rollouts often occur when multiple features share a common component. Do the organic algorithm updates and snippet/ knowledge panel updates rely on the same underlying microservice or technological capability?
Although Query Intent has always been a part of search algorithms, the rise of Voice Search and Mobile Search have made it increasingly important. Google is clearly still actively developing their understanding of what searchers are trying to accomplish with a given query, and making it as easy as possible for them to accomplish that. For example, in February they rolled out multifaceted featured snippets to “better understand your query and recognize when there could be multiple interpretations of that query”.
And immediately following the August Core Algorithm Update, Google announced subtopics within knowledge panels:
This new format is meant to help guide you with what we understand to be common, useful aspects of the topic and help you sift through the information available, all with the goal of delivering the most relevant results for you…These new panels are automatically generated based on our understanding of these topics from content on the web…This update is the latest in a series of improvements we’ve been making to help you get information quickly with Search.
In other words, Google understands that every query has multiple related subtopics that a user may want to explore in order to be “fully satisfied”. They care enough about addressing these additional intent aspects that they’ve expanded both knowledge panels and featured snippets. It’s not much of a leap to say that Google would also want to leverage this understanding within the main organic results as part of the “series of improvements
SEO that works too well is a bug
In addition to strengthening the role of user intent, the August Broad Core Algorithm update, as with many Google updates, seemed to be specifically targeting a few “trouble spots”.
Every SEO technique goes through a similar evolution:
- Some brilliant SEO mad scientist discovers new tactic X that works extremely well.
- To attract clients and grow her reputation, she starts telling others about X.
- Word spreads as more and more businesses get good results using X.
- Some entrepreneur figures out how to do X 10,000 times a day.
- X is now cheap and easy, and people start to complain about it driving up sub-par results.
- Google releases update targeting X.
An example of a tactic that has gone through this entire evolution recently is scholarship links. Once a reasonable way to round out your link profile with a few high authority links, scholarship links are now so widespread and abused that some scholarship lists read like an attendee list for Spammers Anonymous:

We noticed several sites with a preponderance of scholarship links in their backlink profile take a dive on August 1. Good news though, company offering that $200 “Best Mesothelioma Lawyer Scholarship”: you can still feel good about helping college students, in your own very small weirdly-named way.
A much larger scale and more intractable form of SERP manipulation is the power of networks. Networks take many forms, but a particularly dominant one right now is large media conglomerates interlinking their properties to boost rankings of content that otherwise combines mediocre quality with a flood of abusive ads.
Smaller publishers would never get away with this kind of interlinking, but since these are large corporations who generate a lot of revenue for Google, it seems to be OK.
More than OK, in fact: by some estimates, just 16 companies are dominating the majority of valuable keywords in dozens of valuable niches. Media conglomerates are able to launch brand new websites, interlink them with established properties, and get them ranking for thousands of valuable keywords within a matter of months.
These strategies helped Hearst launch BestProducts.com to almost 4 million organic visitors per month in about a year. IAC did the same with VeryWellFamily in only four months. TheBalanceCareers hit over 7 million monthly organic in less than 3 months.
Glen Allsopp AKA ViperChill did an excellent exposé showing how media conglomerates interlink their huge networks of sites to boost authority and dominate search rankings:
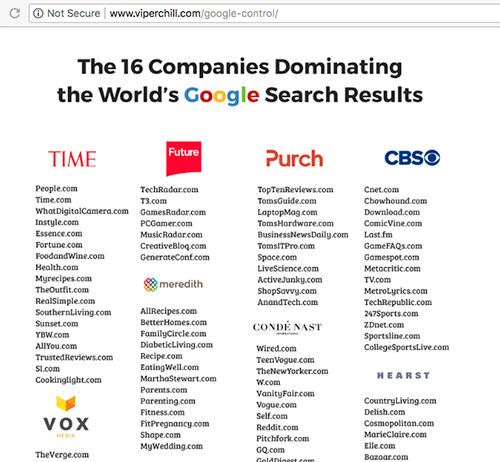
After the August Core Algorithm update, many of these artificially boosted sites have seen organic traffic declines in the range of 20-30%.
Some of the sites that are part of a network and saw significant rankings declines (numbers per SEMRush):
- BestProducts.com: -21%
- Prevention.com: -57%
- Health.com: -13%
- LouderSound.com: -36%
- VeryWellFamily.com: -26%
- MensHealth.com: -20%
- WomensHealth.com: -17%
- TheBalanceCareers.com: -21%
- TheCarConnection.com: -16%
- TrustedReviews.com: -19%
- ExtremeTerrain.com: -12%
- ActiveJunky.com: -18%
- TomsITPro.com: -29%
- EatThis.com: -34%
- VeryWellFit.com: -29%
Which sites were impacted by the Google Medic Update?
Despite the moniker, the Medic Update AKA Broad Core Algorithm Update impacted sites in a number of industries beyond health or YMYL sites.
Losers
Below are some of the sites that seem to have lost traffic, organized by category:
Health, Diet, & Lifestyle
- Thedatingdivas.com
- Ketodash.com
- Thepaleodiet.com
- Organicfacts.net
- Selfhacked.com
- Fleabites.net
- Drugabuse.com
- Naturallivingideas.com
- Verywellfamily.com
- Menshealth.com
- Womenshealthmag.com
- Health.com
- Paleohacks.com
- Fitbottomedgirls.com
- PharmacistAnswers.com
- TabataTimes.com
- DrAxe.com
- Mercola.com
- EatThis.com
- Lilluna.com
- BettyCrocker.com
Finance
- ESIMoney.com
- Bonsaifinance.com
- Thebalancecareers.com
- Insurance.com
Automotive
- TheCarConnection.com
- CarGurus.com
Ecommerce
- Vapordna.com
- Crutchfield.com
- Myprotein.com
- DirectVapor.com
- Extremeterrain.com
- CharlotteRusse.com
- AxonOptics.com
- REI.com
- GNC.com
- BodyBuilding.com
Sports & Outdoors
- CampingManiacs.com
- K9ofmine.com
- ActiveJunky.com
Entertainment (Gaming, Music, TV)
- Kotaku.com.au
- Nerdist.com
- Deezer.com
- Loudersound.com
- PCGamer.com
- PCGames.de
- MetroLyrics.com
Travel
- Travelocity.com
- LonelyPlanet.com
Reviews
- Bestproducts.com
- TrustedReviews.com
- ConsumerAffairs.com
- ConsumerReports.org
Politics
- NRA.org
- NationalReview.com
Other
- KhanAcademy.org
- Zesty.io
- TomsITPro.com
- DealsPlus.com
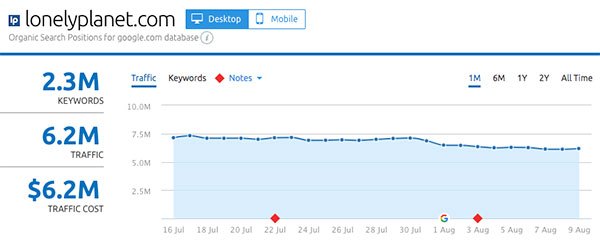
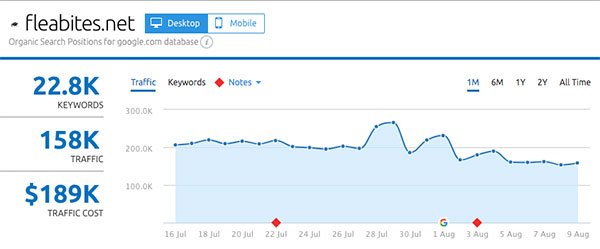
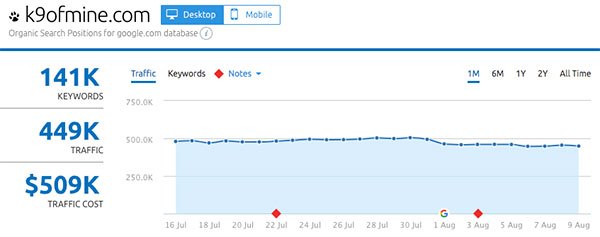
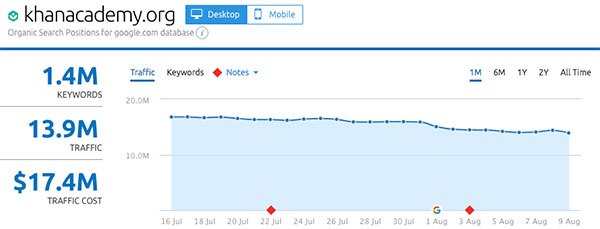
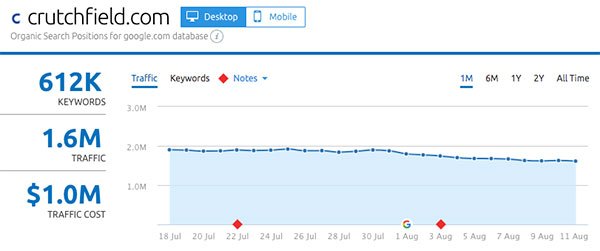
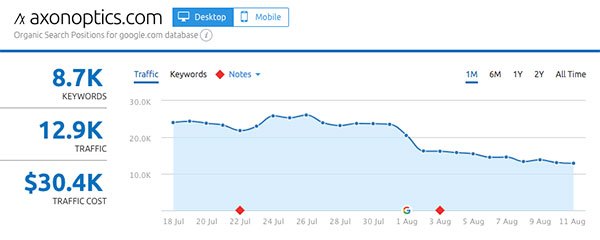
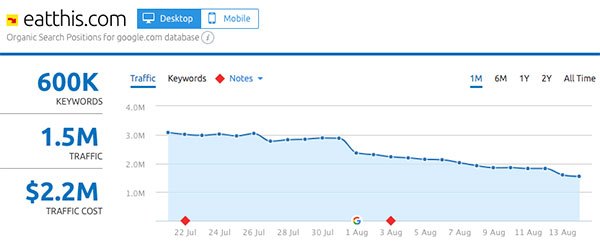
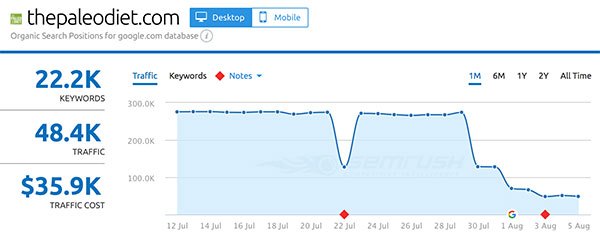
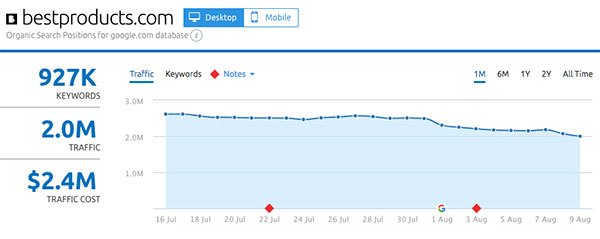
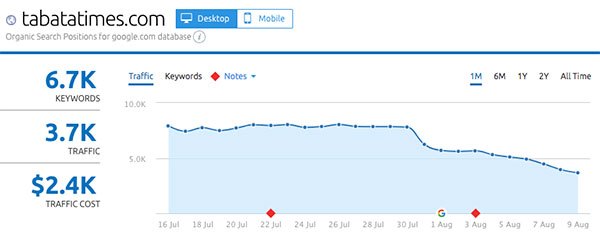
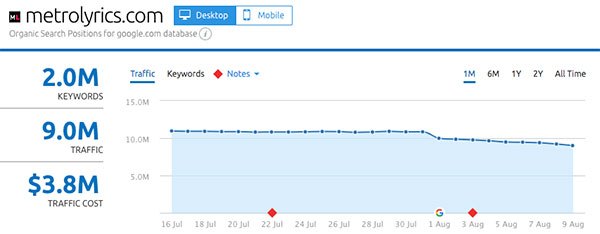
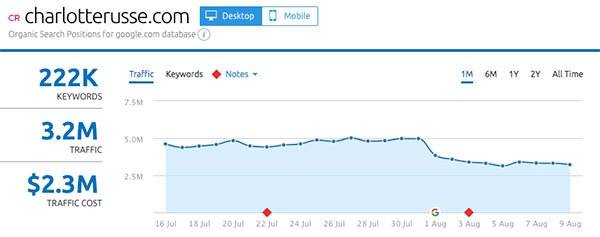
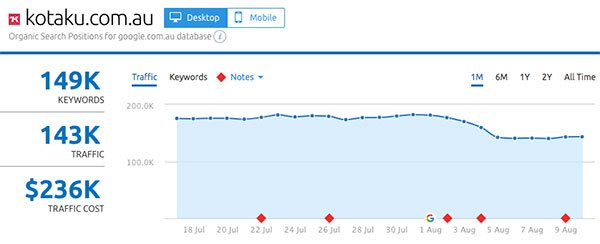
Gainers
Below are some of the sites that seem to have gained traffic since the August 1st Google Update:
Health & Lifestyle
- Drugs.com
- OneCrazyHouse.com
- HealthLine.com
- MedlinePlus.gov
- PopSugar.com
- Examine.com
- DietDoctor.com
- Health24.com
- RXList.com
- UpToDate.com
- Driscolls.com
Finance
- ConsumerismCommentary.com
- Home.loans
- RealisticLoans.com
Coupons
- CouponFollow.com
- CouponCabin.com
Automotive
- CarFax.com
- AutoTrader.com
Ecommerce
- Mister-e-liquid.com
- GamesGames.com
- Mozaico.com
- eBay.com
- REI.com
- ElementVape.com
- Backcountry.com
Sports & Outdoors
- Runtastic.com
- MuscleAndBrawn.com
- Goal.com
- CleverHiker.com
Digital Marketing
- Grow.Google
- Backlinko
- Startups.co
- CanIRank
Entertainment (Gaming, Music, TV)
- ScreenRant.com
- Polygon.com
Travel
- Oyster.com
Reviews
- Reviews.com
- TheWirecutter.com
Politics
- FoxNews.com
- YourNewswire.com
Other
- Glassdoor.com
- SodaPDF.com
- UrbanDictionary.com

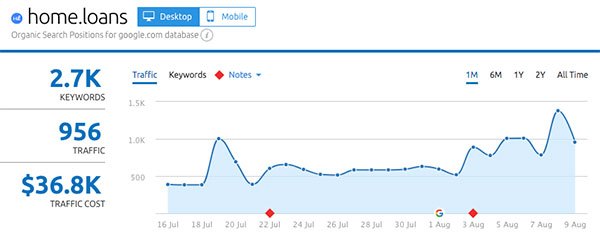
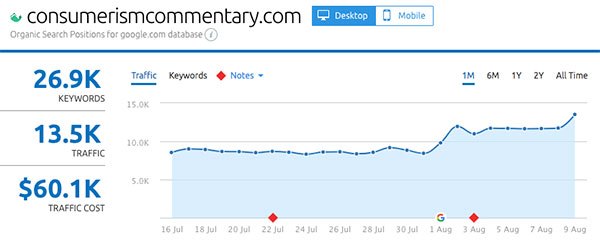
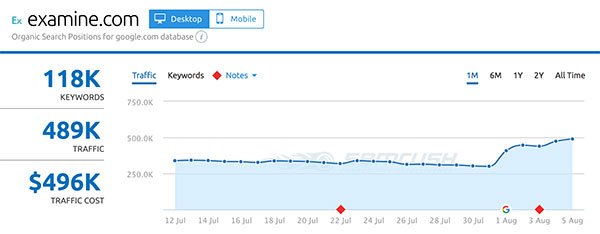
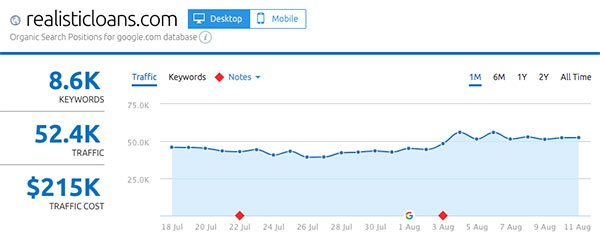
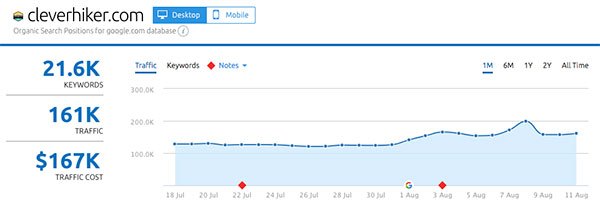

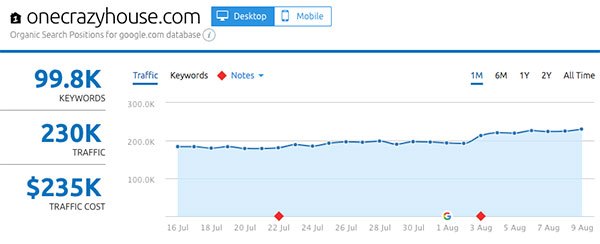
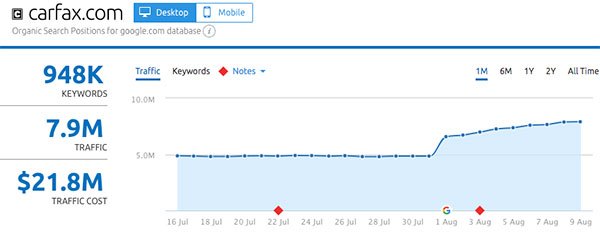
Up next: what actually changed in the Medic Update?
In Part 2 we’ll dive into actual data collected from almost 100 websites that saw significant gains or losses starting August 1st, to see which factors were associated with increases and which were seen in many of the losing sites.



Leave A Comment