
Search ranking factor correlation studies are bullshit.
In the past year, nearly every major SEO media outlet has published its own variation of a search ranking factor correlation study. They scrape huge numbers of search engine ranking results and calculate the correlation between Google rank and various SEO metrics such as the number of links, keyword density, or CTR.
These correlations, the study authors claim, indicate the relative importance of various search ranking factors in Google’s algorithm. A factor with a high correlation is more important than a factor with a low correlation, and we should adjust our SEO accordingly.
Unfortunately, it’s total bullshit. Such conclusions are unsupported speculation at best, and dangerously misleading at worst.
In this post we’ll look at some of the reasons ranking factor correlation studies are not a useful way to measure the relative importance of search ranking factors, and show you some alternatives you might consider instead.
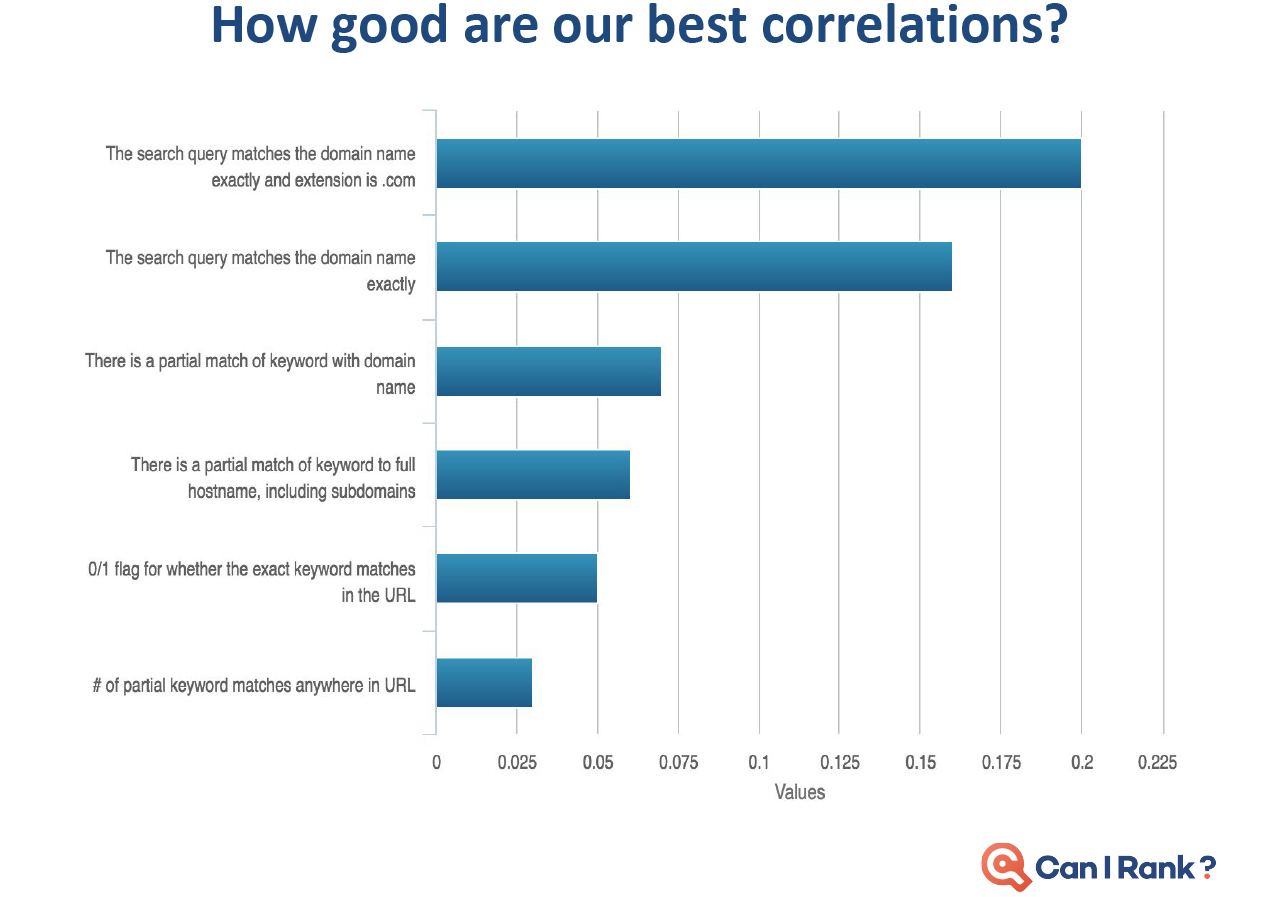
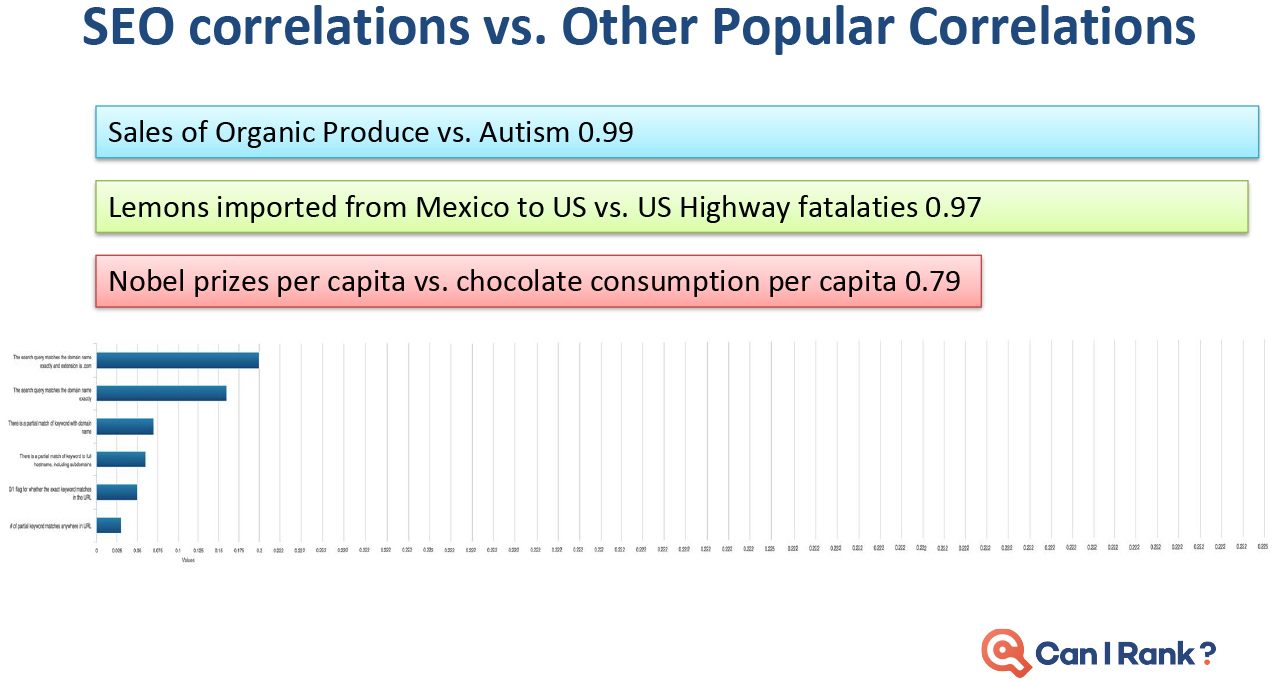
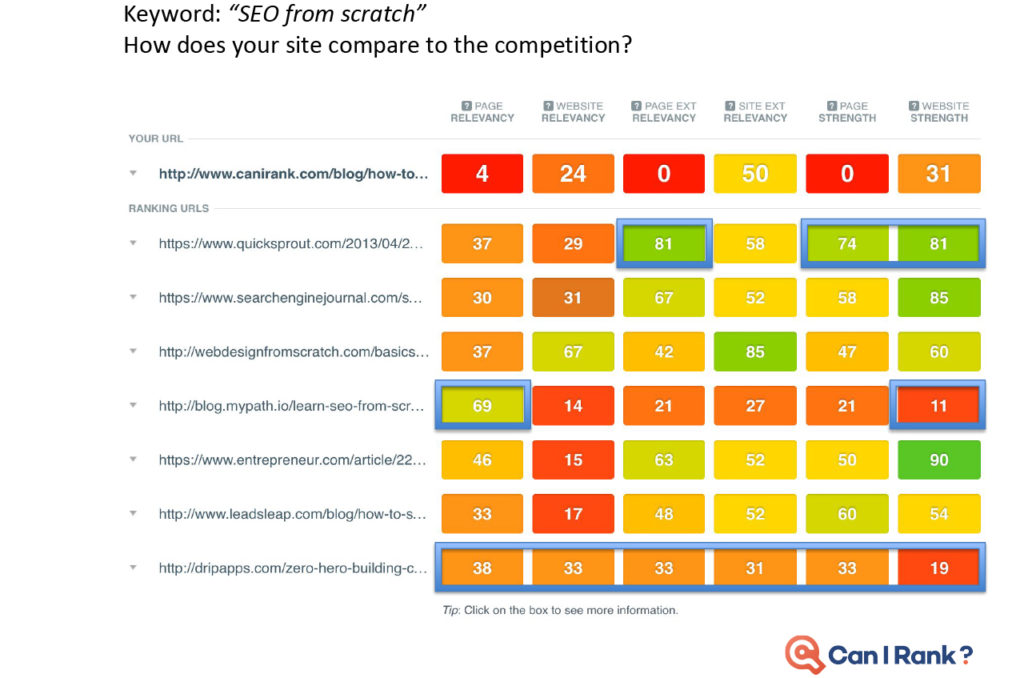
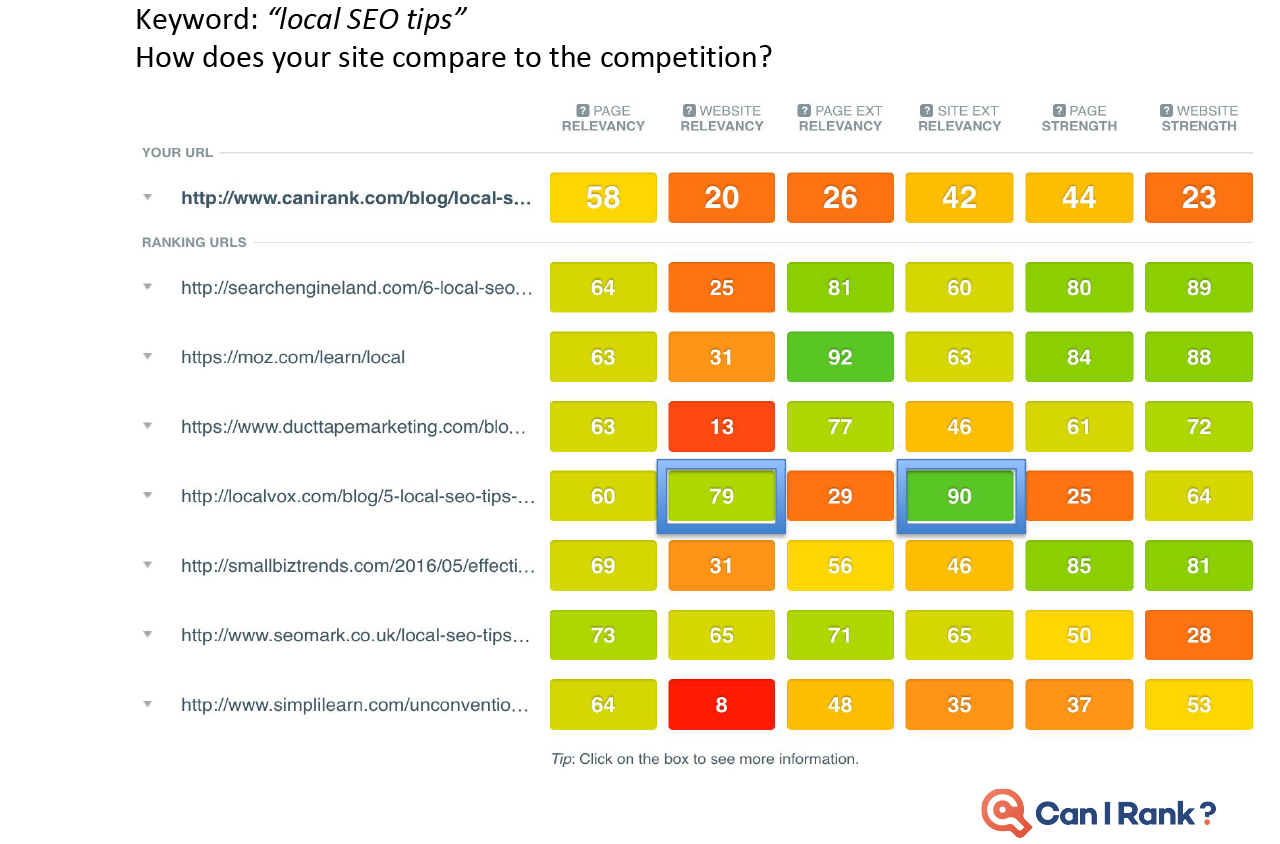
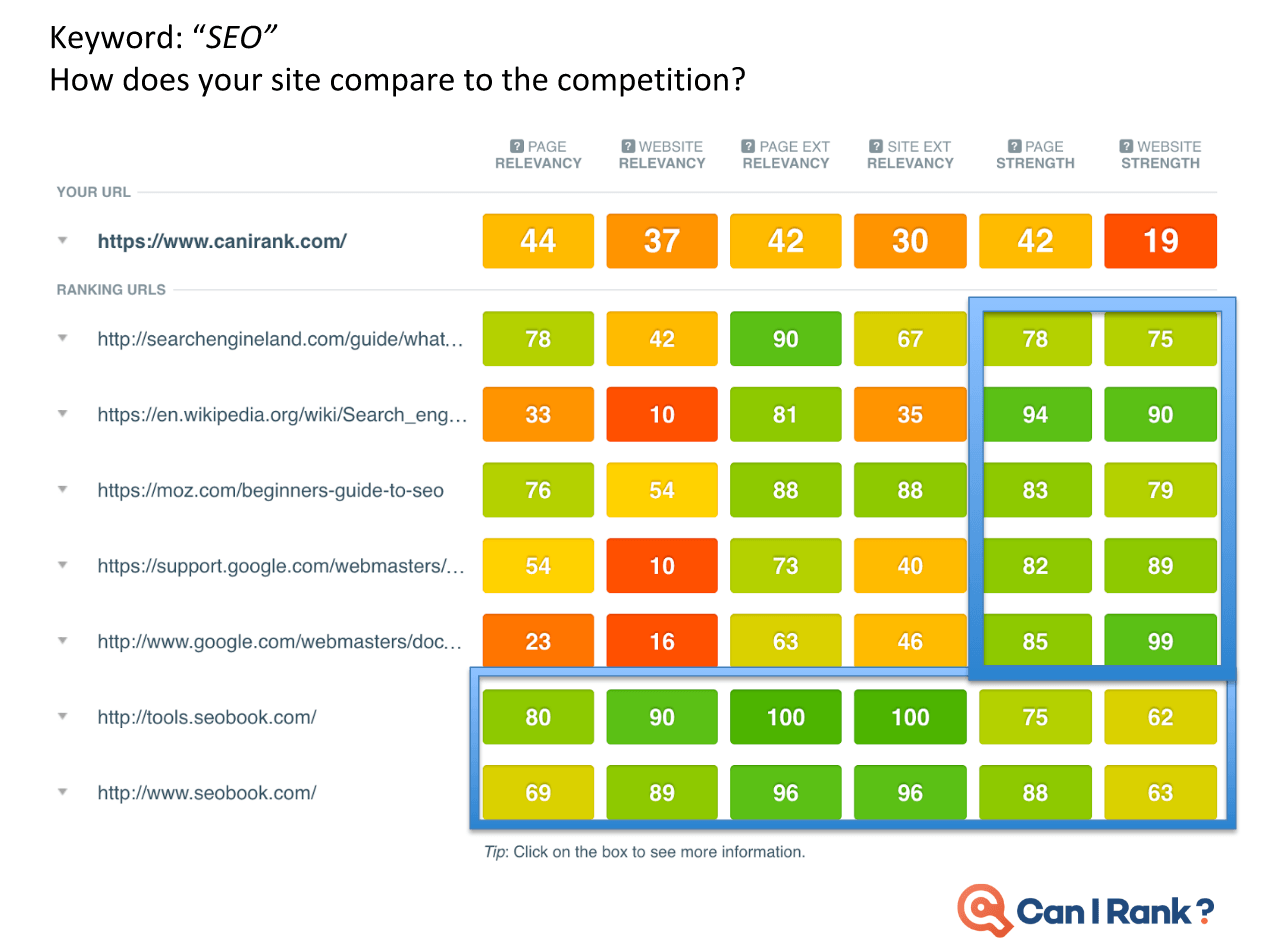
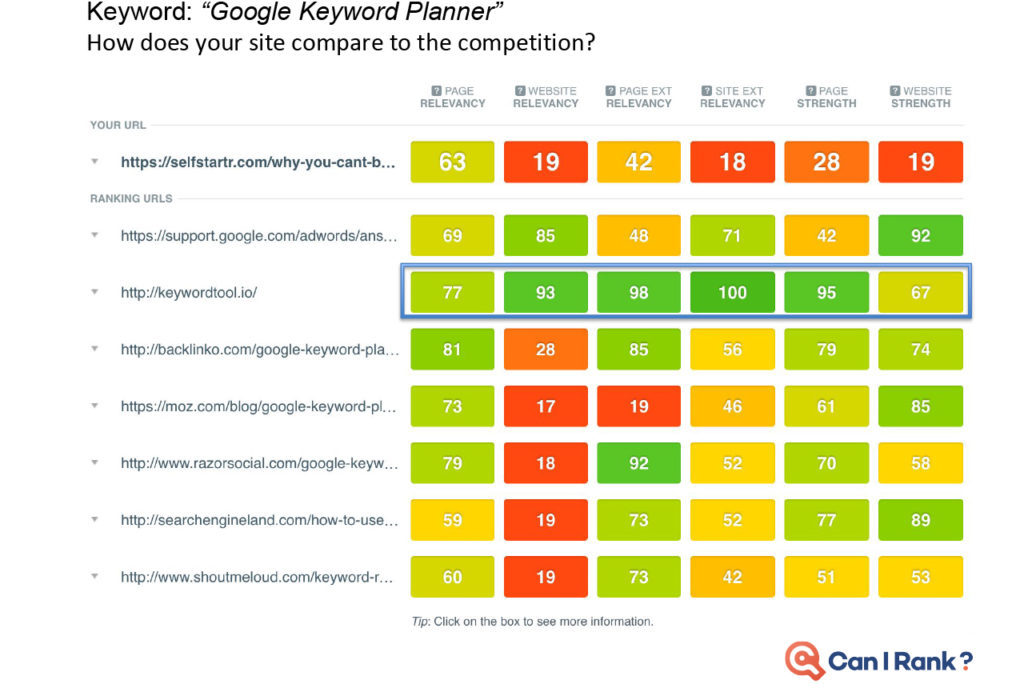
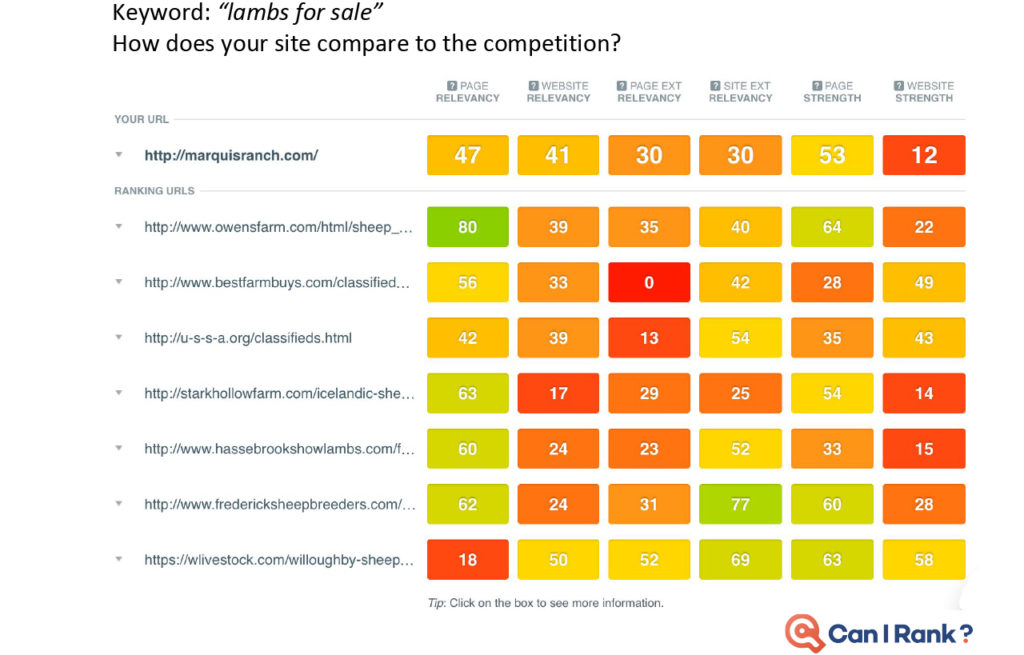
Today’s professional SEOs are largely intelligent and analytical marketers who understand the need to ground decisions in a thorough analysis of the data around what works and why. Yet the limited availability of accurate SEO data for search engine rankings prevents them from becoming more data-driven.” Faulty studies and misinterpreted results just make things worse. As marketers in other areas embrace a new era of data-driven performance built on sophisticated machine learning algorithms and statistical analysis techniques, SEO risks being left behind. CanIRank’s new series on data-driven SEO is our attempt to counteract this situation. We want marketers to gain a deeper and more rigorous understanding of the data underlying search engine rankings and SEO decisions. This isn’t for SEOs looking for “simple,” “easy,” or dumbed down explanations. Likewise, it’s not for marketers scared of numbers or statistics. Rather, these posts are for people who have always wanted to peek “behind the curtain” at Google’s algorithms and how the algorithms influence various search ranking factors. Founders who want to become five percent more efficient in their SEO work every month — and understand just how powerful that would be. We’re putting modern SEO best practices under the microscope. You’ll discover which expert recommendations are justified, and which are not. I’ll call on my background as a data scientist, as well as data from the most accurate ranking models outside of Mountain View to help. Think of it as a bit like “Mythbusters for SEO.” Our Data-Driven SEO series has three principal objectives: In this first post of the series, we discuss some limitations of current SEO studies. Plus, we show how and why they’re often misinterpreted. In future posts we’ll look at the data behind SEO questions such as: To get a head’s up about new posts in this series, be sure to follow us on Twitter or Facebook, or better yet, register for a free CanIRank account. So let’s get started. The reality is that most people in SEO are marketers and not data scientists. It’s common for even big names in the SEO industry to publish information and advice that misinterprets data or draws conclusions the data does not support. While sensationalizing and oversimplifying SEO may make for a popular blog post, it’s not necessarily useful. Scientific rigor, on the other hand, certainly won’t make you famous. But it just may make you better at SEO. In other words, talent for self-promotion doesn’t necessarily correlate with SEO ability. As an SEO software company, we have a unique mile-high perspective on the SEO industry due to the thousands of consultants and in-house marketers who use our software. One pattern we’ve noticed is that SEOs who consistently get great results for clients rarely have the biggest Twitter following or the busiest conference speaking schedule. Every hour spent on self-promotion is an hour not spent sharpening skills or helping clients. To stay ahead of the masses, seek out and learn from SEOs who make their living doing, not teaching. Much to the chagrin of people who understand statistics, the SEO industry has popularized the idea that correlation with Google rankings can be used to measure the relative importance of different ranking factors. For example, a study may report that the number of Linking C-Blocks to a domain has a 0.26 correlation with Google rankings while Exact Keyword Density has a 0.14 correlation. Therefore, the authors claim, the number of Linking C-Blocks is a more significant ranking factor than Exact Keyword Density. Unfortunately, there are some flaws in this approach. Let’s examine each in turn. We often see SEO correlations presented on a graph that looks something like this one from the Moz study. (I don’t mean to pick on the good folks from Moz. In my opinion, they’re much better than most when it comes to responsible use of statistics.) Looks promising, doesn’t it? But let’s take another look with those correlations on a scale going from 0 to 1: Already looking a little less compelling, isn’t it? How about we add in a few correlations from outside the SEO world to give some added perspective? Obviously, those are extreme examples, but a typical strong correlation, such as the relationship between height and weight, is usually around 70%. Even the best SEO correlations are significantly weaker. This is partly due to the high degree of noise in web-scale data. Another factor is that all SEO studies use third-party data. Like Plato’s famous allegory, the data we look at is a mere shadow on the cave wall next to the real data locked away inside the walls of the Googleplex. With such messy data and weak correlations, there’s really only one responsible interpretation: “Factor X and Factor Y are both poorly correlated with Google results, but Factor Y slightly less so.” In that context, you can see how crazy it would be to conclude “so definitely make sure you focus on optimizing Factor Y!” It may be the biggest cliche in statistics, but it’s a lesson many are quick to forget in pursuit of a hot story. No matter how seductive it may be, correlation does not equal causation. Here are a couple of examples to illustrate this. Sales of organic produce and autism rates have a very strong 0.99 correlation, suggesting that the former can be used to explain nearly all the variation in the latter. Yet few (hopefully nobody!) would conclude that organic produce causes autism. How about this one? Lemons imported from Mexico to US vs. US Highway fatalities have an equally impressive correlation of 0.97. Who would conclude that importing lemons from Mexico leads to traffic accidents? So there is good reason to be wary of SEO studies drawing similar conclusions based on much weaker correlations. Finally, know that if you look at enough metrics, even if they’re all completely unrelated, you will find ones with strong correlations. The most famous example of this phenomenon was illustrated by Caltech’s David Leinweber. Mining a database of agricultural statistics, he found that butter production in Bangladesh had a 75% correlation with the movements of the S&P 500. Add in US Butter production and Cheese production, and you can explain 95% of the variation in the S&P 500. Add in the population of Sheep in the US and Bangladesh, and you can “explain” 99% of the movements in the S&P 500 benchmark! Imagine the buzz in the SEO industry if a handful of metrics of Google searches could predict 99% of the variations in Google rankings. “Secrets of Google’s algorithm finally revealed!” Yet if you study enough metrics, it’s not only likely, it’s inevitable that you will find some that correlate well with Google rankings. Rather than drawing conclusions from correlations alone (or rejecting them outright), treat that as step 1. Then start digging deeper to see if you can understand the actual mechanism at work. That requires developing a more nuanced understanding of search ranking algorithms, so let’s start peeling that onion. One of the reasons that SEO correlations are so poor is that sites can rank for a variety of reasons. Searches with various types of queries (navigational, informational, commercial, etc.) and different kinds of keywords (from one-word big brands to long-tail gibberish) return result sets with different characteristics.” Correlation studies attempt to bulldoze over those differences, pretending that all #1 ranking results are equal, as are #2 ranking results, and so on. Let’s look at some examples to see how ridiculous this approach actually is. Take a look at this CanIRank competitive analysis report for the keyword “SEO from scratch”. All these pages rank well, but each ranks for a different reason. QuickSprout has the top spot due to Page Strength and Website Strength, plus some excellent anchor text. Mypath ranks well thanks to high Page Relevancy; they’re the only one actually targeting this particular phrase. WebDesignFromScratch benefits from the keywords in their domain name boosting their Website External Relevancy. DripApps makes the cut just by being average at everything. Their strength lies in their consistency. Here’s the CanIRank report for the keyword “local SEO tips”. Notice Localvox in fourth place on the list. This site scores lower in most of the categories compared to other sites on the list. But since the entire website is focused on local SEO tips, it has high Website Relevancy and high Website External Relevancy scores. In the competitive analysis table for the keyword “SEO“, Big brands like Search Engine Land, Moz, Wikipedia, and Google rank largely thanks to their Website Strength and Page Strength. Meanwhile, SEOBook manages a double-header showing because they’ve done very well on nearly all of the factors except Page Strength and Website Strength. Here’s an example of the search term “Google keyword planner”. You might think that Keywordtool.io would rank #1. After all, they’re stronger in almost every ranking factor. However, Google understands in this instance that the searcher is probably looking for a specific product brand. Sometimes pages rank well despite being weak in every area.” to “Sometimes pages rank well for keyword searches despite being weak in every area. Sometimes pages rank well despite being weak in every area. Here’s an example from an industry far removed from SEO. The keyword phrase “lambs for sale” has little competition compared to SEO industry terms. Only the top ranking page is well-optimized for their target keyword searches. For this keyword, the #1 ranking result is probably weaker than the 586th highest ranked result for the keyword “SEO.” Bottom line, not all results are playing by the same rules. Measuring correlations over a population of result sets this diverse is tough. Theoretically, we can “smooth over” these differences with sheer volume of data collected. But these are not small bumps you can simply iron out. These are Everest-sized mountains — fundamental differences you can’t smooth over even with a massive data set. There’s a reason search result sets tend to look so different. It’s inherent in the nature of search engine algorithms, so we’ll explore that next. SEOs tend to oversimplify search engine algorithms. Search engines aren’t a simple linear point-based system like you might use to rank football teams. It’s not like you have 10 of those, 6 of these, and 4 of that, and therefore will outrank another site that only has 9 of those, 5 of these, and 3 of that. In modern search engines, it’s more accurate to envision many interconnected algorithms at work. Some of these algorithms may be rule or point-based, while others act more like classifiers. For example, a classification algorithm may be used to determine whether a certain page is a “store” or a “review blog”. For a given product search, Google rankings factors may decide to return a 80% commercial stores where the user can buy that product and 20% informational reviews of that product. If your page looks like a store, you’re competing against Amazon, Walmart, Ebay, and other massive etailers. But if you look like a review, your competition is limited to a handful of other review bloggers — and sometimes no one at all. (We explain this strategy in more detail in our post on how to outrank Amazon.) Weaker can outrank stronger. Sometimes it’s not “Do you have more links than the other guy?” but rather “What kind of site do you look like?” At other times, scoring too high in one metric (such as exact match anchor text) can get you labeled a spammer. Too low and you’re irrelevant. The best score is actually one somewhere in the middle, and that sweet spot may vary by keyword. Correlations aren’t able to reflect that kind of non-linearity. It’s rare that you can make a determination based on just one factor in isolation. To be prescriptive in figuring out how to improve a site based on data you need to understand: Search ranking algorithms are more layered and complex than many SEOs imagine. Simplistic correlation studies reinforce this misperception by implying that more is always better. While other people look at correlations, we try to understand why sites rank. Correlations and other descriptive statistics are merely a symptom of some underlying mechanism. If you understand the mechanism at work, you can turn correlations and other data into actionable insights. CanIRank aggregates over 200 individual SEO metrics into six major Ranking Factor areas to make it easier for humans to understand and visualize the interactions at work. This helps smooth over some of the noise of the messy underlying data, and see what factors the algorithm emphasizes for any keyword. What happens when you take the average of a diverse population? Characteristics of the largest sub-group within that population will dominate the averages. You’ll end up with a messy, watered-down description of that dominant sub-group, rather than a description of the population overall. In the case of SEO correlation studies, that dominant sub-population is Big Brand websites. If you do the kind of naive analysis that most studies perform, you end up concluding that top-ranking pages: That more or less describes the characteristics of a Big Brand site. But these posts go on to conclude that “therefore you should use https, use shorter URLs, get more links, etc…” But being a Big Brand isn’t the only path to top rankings, and it’s much more actionable for us to know how sites like ours manage to rank well. We’re interested in the exceptions, not the rule. Understanding the characteristics of small and medium-sized sites who make it on to page 1 is often much more actionable than taking an average across all top-ranking sites. Not all data is created equally. Analyzing sample size, error rate, distribution, and other characteristics allow us to determine whether or not we can rely upon the conclusions of a given study. Unfortunately, SEO studies rarely include that level of detail. If people are betting their livelihood on the conclusions presented in a study, it seems reasonable to have some indication whether the data is reliable. One possible solution would be to introduce a standard indicating the robustness of any conclusion presented. Conclusions could be graded on a scale from “Unclear conjecture” to “Extremely reliable”. Below is a simple Data Robustness scale I included in my presentations at this year’s Ungagged Conference. Without having to get into any statistical nitty gritty, attendees could distinguish between conclusions that were strongly supported by clear data and those that were more speculative. A robust conclusion means a large sample size, clear patterns relative to the noise or variance, and metrics not prone to error. Less robust conclusions based upon small sample sets or “aggressively cleaned” data could be labeled as such. Data varies widely in its characteristics, so accompanying SEO studies with a reliability indicator would go a long way towards helping readers determine whether or not they should act upon a study’s conclusions. We’ll include a Data Robustness indicator with all of our study conclusions here on the CanIRank blog, and if any other SEO blogs would like to work on a common standard, we’d certainly welcome that. The next time you read an SEO study, be wary of authors who draw conclusions based upon correlations alone. Think about what underlying mechanisms might be driving those correlations, and attempt to isolate the individual search ranking factors at work by controlling for other factors or limiting population diversity. Remember that correlations obfuscate a good deal of underlying complexity — and sometimes it’s that very complexity that opens the door to outranking our competition. Read: Data-driven SEO Part 2: Does Long Content Really Rank Better? Is the Data Science Revolution Leaving SEO Behind?
Can You Trust SEO Experts?
Can You Trust SEO Correlation Studies?
Even the Best SEO Correlations Are Not That Good

Correlation Does Not Equal Causation
Sites Rank for Different Reasons
Algorithms for Search Ranking Factors Are Nonlinear
A More Nuanced Way to Look at SEO Data
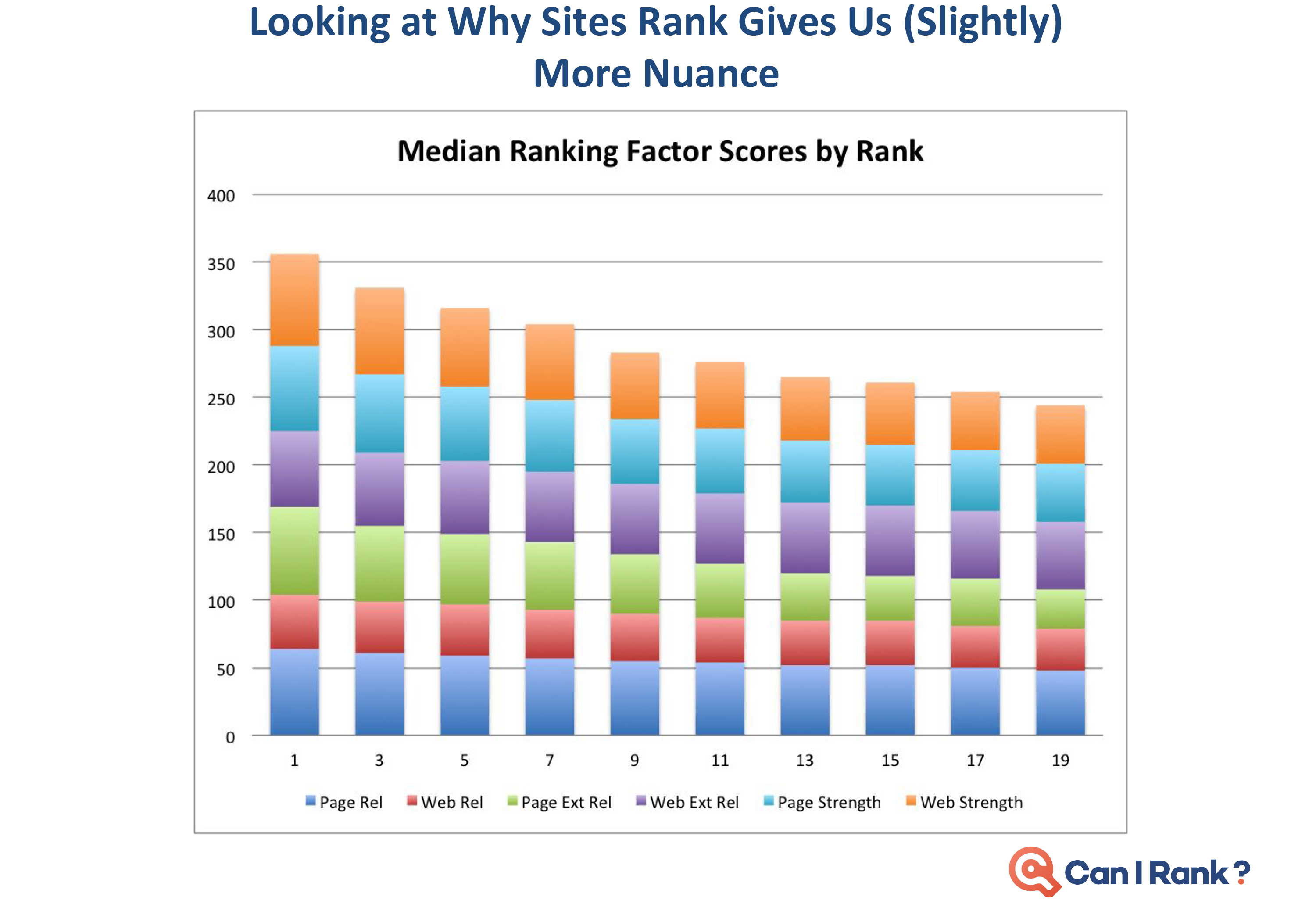
What are correlation studies really showing us?
How Robust Are SEO Studies?

Take Action



Matt,
Great article and it sparked a lot of interesting conversation in my mastermind.
I wanted to ask a follow-up question in regards to your overall stance that correlation studies are not good.
Is it that you are against the way the studies are conducted, focusing on a correlation of sites that typically rank high, i.e. big websites versus looking at correlation in a more microscopic view, i.e. looking at the correlation of ranking factors for a specific keyword.
Or
Are you saying that correlation is a bad way to look at SEO data all together?
Clint – both to an extent. Search rankings are complex enough that correlation studies end up smoothing over the nuances that you need to dig into if you really want to understand how search ranking algorithms work. Analyzing one keyword at a time obviously precludes statistical validity but is often more likely to turn up actionable insights — ie, help you determine what it will take to rank for that specific keyword.